Tutorial#
Before You Begin#
Note
NSLS-II deploys a free, public “sandbox” for trying the software in the browser using Jupyter notebooks. There will be no need to install any software, and you can skip the rest of this section. Go to https://try.nsls2.bnl.gov.
You will need Python 3.10 or newer. From a shell (“Terminal” on OSX, “Command Prompt” on Windows), check your current Python version.
python3 --versionIf that version is less than 3.10, you must update it.
We recommend install bluesky into a “virtual environment” so this installation will not interfere with any existing Python software:
python3 -m venv ~/bluesky-tutorial source ~/bluesky-tutorial/bin/activate
Alternatively, if you are a conda user, you can create a conda environment:
conda create -n bluesky-tutorial "python>=3.10" conda activate bluesky-tutorial
Install the latest versions of bluesky and ophyd. Also install Tiled and bluesky-tiled-plugins unless you plan to skip the sections about accessing saved data. If you want to follow along with the visualization examples, install matplotlib and PyQt5. Finally, install IPython (a Python interpreter designed by scientists for scientists).
python3 -m pip install --upgrade bluesky ophyd "tiled[all]" bluesky-tiled-plugins matplotlib pyqt5 ipython pyepics
Alternatively, if you are a conda user and you prefer conda packages, you can use:
conda install -c conda-forge bluesky ophyd tiled bluesky-tiled-plugins matplotlib pyqt=5 ipython
Start IPython:
ipython --matplotlib=qt5
The flag
--matplotlib=qt5is necessary for live-updating plots to work.Or, if you wish you use bluesky from a Jupyter notebook, install a kernel like so:
ipython kernel install --user --name=bluesky-tutorial --display-name "Python (bluesky)"
You may start Jupyter from any environment where it is already installed, or install it in this environment alongside bluesky and run it from there:
pip install notebook jupyter notebook
If you get lost or confused…#
…then we want to know! We have a friendly chat channel to let us know where our documentation could be made more clear.
The RunEngine#
Bluesky encodes an experimental procedure as a plan, a sequence of atomic instructions. The RunEngine is an interpreter for plans. It lets us focus on the logic of our experimental procedure while it handles important technical details consistently: it communicates with hardware, monitors for interruptions, organizes metadata and data, coordinates I/O, and ensures that the hardware is left in a safe state at exit time.
This separation of the executor (the RunEngine) from the instruction set (the plan) pays off in several ways, as we will see in the examples that follow.
Note
If you are a visiting user at a facility that runs bluesky, you can skip this section and go straight to Common Experiments (“Plans”). A RunEngine will have already been configured for you. If you ignore this and define your own, you may be overriding pre-configured defaults, which can result in data loss.
To check, type RE. If a RunEngine has already been configured, you
should get something like:
In [1]: RE
Out[1]: <bluesky.run_engine.RunEngine at 0x10fd1d978>
and you should skip the rest of this section. But if this gives you a
NameError, you’ll need to finish this section.
Create a RunEngine:
from bluesky import RunEngine
RE = RunEngine({})
This RunEngine is ready to use — but if you care about visualizing or saving your data, there is more to do first….
During data acquisition, the RunEngine dispatches a live stream of metadata and data to one or more consumers (“callbacks”) for in-line data processing and visualization and long-term storage. Example consumers include a live-updating plot, a curve-fitting algorithm, a database, a message queue, or a file in your preferred format. See Live Visualization and Processing for more detail.
Prepare Live Visualization#
To start, let’s use the all-purpose
BestEffortCallback.
from bluesky.callbacks.best_effort import BestEffortCallback
bec = BestEffortCallback()
# Send all metadata/data captured to the BestEffortCallback.
RE.subscribe(bec)
The BestEffortCallback will receive the
metadata/data in real time and produce plots and text, doing its best to
provide live feedback that strikes the right balance between “comprehensive”
and “overwhelming.”
For more tailored feedback, customized to a particular experiment, you may
configure custom callbacks. Start by reading up on Documents, the
structure into which bluesky organized metadata and data captured during an
experiment. But for this tutorial and for many real experiments, the
BestEffortCallback will suffice.
Prepare Data Storage#
Tiled is a service for searchable access to metadata and data generated by bluesky. The bluesky-tiled-plugins package provides the callback that writes bluesky runs into Tiled. For this tutorial, we will spin up a local Tiled server backed by temporary storage.
from bluesky_tiled_plugins.writing.tiled_writer import TiledWriter
from tiled.client import simple
db = simple()
# Insert all metadata/data captured into db.
RE.subscribe(TiledWriter(db))
Warning
This example makes temporary storage. Do not use it for important
data. The data will become difficult to access once Python exits or the
local Tiled server is stopped. Creating a new SimpleTiledServer without
a persistent directory creates fresh, separate temporary storage.
Add a Progress Bar#
Optionally, you can configure a progress bar.
from bluesky.utils import ProgressBarManager
RE.waiting_hook = ProgressBarManager()
See Progress Bar for more details and configuration.
Let’s take some data!
Common Experiments (“Plans”)#
Read Some Detectors#
Begin with a very simple experiment: trigger and read some detectors. Bluesky calls this “counting”, a term of art inherited from the spectroscopy community.
For this tutorial, we will not assume that you have access to real detectors or motors. In the examples that follow, we will use simulated hardware from ophyd, a library developed in tandem with bluesky. In a later section we will see what it looks like to configure real hardware with ophyd.
from ophyd.sim import det1, det2 # two simulated detectors
Using the RunEngine, RE, “count” the detectors:
from bluesky.plans import count
dets = [det1, det2] # a list of any number of detectors
RE(count(dets))
Demo:
In [2]: RE(count(dets))
Transient Scan ID: 1 Time: 2026-07-13 13:54:16
Persistent Unique Scan ID: 'c3612b5a-7595-412b-9cf6-9f52705ed967'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | det1 | det2 |
+-----------+------------+------------+------------+
| 1 | 13:54:16.4 | 0.000 | 1.213 |
+-----------+------------+------------+------------+
generator count ['c3612b5a'] (scan num: 1)
Out[2]: ('c3612b5a-7595-412b-9cf6-9f52705ed967',)
A key feature of bluesky is that these detectors could be simple photodiodes or complex CCDs. All of those details are captured in the implementation of the Device. From the point of view of bluesky, detectors are just Python objects with certain methods.
See count() for more options. You can also view this
documentation in IPython by typing count?.
Try the following variations:
# five consecutive readings
RE(count(dets, num=5))
# five sequential readings separated by a 1-second delay
RE(count(dets, num=5, delay=1))
# a variable delay
RE(count(dets, num=5, delay=[1, 2, 3, 4]))
The count() function (more precisely, Python generator
function) is an example of a plan, a sequence of instructions encoding an
experimental procedure. We’ll get a better sense for why this design is useful
as we continue. Briefly, it empowers us to:
Introspect the instructions before we execute them, checking for accuracy, safety, estimated duration, etc.
Interrupt and “rewind” the instructions to a safe point to resume from, both interactively and automatically (e.g. in the middle of the night).
Reuse a generic set of instructions on different hardware.
Modify the instructions programmatically, such as inserting a set of baseline readings to be taken automatically before every experiment.
Warning
Notice that entering a plan by itself doesn’t do anything:
In [3]: count(dets, num=3)
Out[3]: <generator object count at 0x7f9037250e00>
If we mean to execute the plan, we must use the RunEngine:
In [4]: RE(count(dets, num=3))
Transient Scan ID: 2 Time: 2026-07-13 13:54:16
Persistent Unique Scan ID: '39e6a899-944b-4b72-9d80-93c2ba16dcad'
New stream: 'primary'
+-----------+------------+------------+
| seq_num | time | det |
+-----------+------------+------------+
| 1 | 13:54:16.7 | 0.000 |
| 2 | 13:54:16.8 | 0.000 |
| 3 | 13:54:16.9 | 0.000 |
+-----------+------------+------------+
generator count ['39e6a899'] (scan num: 2)
Out[4]: ('39e6a899-944b-4b72-9d80-93c2ba16dcad',)
Scan#
Use scan() to scan motor from -1 to 1 in ten
equally-spaced steps, wait for it to arrive at each step, and then trigger and
read some detector, det.
from ophyd.sim import det, motor
from bluesky.plans import scan
dets = [det] # just one in this case, but it could be more than one
RE(scan(dets, motor, -1, 1, 10))
In [5]: RE(scan(dets, motor, -1, 1, 10))
Transient Scan ID: 3 Time: 2026-07-13 13:54:17
Persistent Unique Scan ID: '70bfab7b-20b7-4a96-9f07-47e5961d2df5'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | motor | det |
+-----------+------------+------------+------------+
| 1 | 13:54:17.3 | -1.000 | 0.607 |
| 2 | 13:54:17.3 | -0.778 | 0.739 |
| 3 | 13:54:17.4 | -0.556 | 0.857 |
| 4 | 13:54:17.4 | -0.333 | 0.946 |
| 5 | 13:54:17.5 | -0.111 | 0.994 |
| 6 | 13:54:17.6 | 0.111 | 0.994 |
| 7 | 13:54:17.6 | 0.333 | 0.946 |
| 8 | 13:54:17.7 | 0.556 | 0.857 |
| 9 | 13:54:17.7 | 0.778 | 0.739 |
| 10 | 13:54:17.8 | 1.000 | 0.607 |
+-----------+------------+------------+------------+
generator scan ['70bfab7b'] (scan num: 3)
Out[5]: ('70bfab7b-20b7-4a96-9f07-47e5961d2df5',)
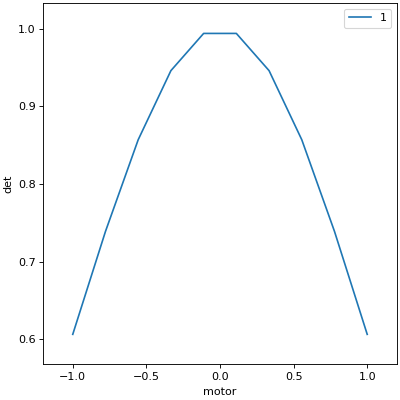
Again, a key feature of bluesky is that motor may be any “movable” device,
including a temperature controller, a sample changer, or some pseudo-axis. From
the point of view of bluesky and the RunEngine, all of these are just objects
in Python with certain methods.
In addition the producing a table and plot, the
BestEffortCallback computes basic peak
statistics. Click on the plot area and press Shift+P (“peaks”) to visualize
them over the data. The numbers (center of mass, max, etc.) are available in a
dictionary stashed as bec.peaks. This is updated at the end of each run.
Of course, if peak statistics are not applicable, you may just ignore this
feature.
Use rel_scan() to scan from -1 to 1 relative to
the current position.
from bluesky.plans import rel_scan
RE(rel_scan(dets, motor, -1, 1, 10))
Use list_scan() to scan points with some arbitrary
spacing.
from bluesky.plans import list_scan
points = [1, 1, 2, 3, 5, 8, 13]
RE(list_scan(dets, motor, points))
For a complete list of scan variations and other plans, see Plans.
Scan Multiple Motors Together#
There are two different things we might mean by the phrase “scan multiple motors ‘together’”. In this case we mean that we move N motors along a line in M steps, such as moving X and Y motors along a diagonal. In the other case, we move N motors through an (M_1 x M_2 x … x M_N) grid; that is addressed in the next section.
SPEC users may recognize this case as analogous to an “a2scan” or “d2scan”, but with an arbitrary number of dimensions, not just two.
We’ll use the same plans that we used in the previous section. (If you already imported them, there is no need to do so again.)
from bluesky.plans import scan, rel_scan
We’ll use two new motors and a new detector that is coupled to them via
a simulation. It simulates a 2D Gaussian peak centered at (0, 0).
Again, we emphasize that these “motors” could be anything that can be “set”
(temperature controller, pseudo-axis, sample changer).
from ophyd.sim import det4, motor1, motor2
dets = [det4] # just one in this case, but it could be more than one
The plans scan() and rel_scan()
accept multiple motors.
RE(scan(dets,
motor1, -1.5, 1.5, # scan motor1 from -1.5 to 1.5
motor2, -0.1, 0.1, # ...while scanning motor2 from -0.1 to 0.1
11)) # ...both in 11 steps
The line breaks are intended to make the command easier to visually parse. They are not technically meaningful; you may take them or leave them.
Demo:
In [6]: RE(scan(dets,
...: motor1, -1.5, 1.5, # scan motor1 from -1.5 to 1.5
...: motor2, -0.1, 0.1, # ...while scanning motor2 from -0.1 to 0.1
...: 11)) # ...both in 11 steps
...:
Transient Scan ID: 4 Time: 2026-07-13 13:54:19
Persistent Unique Scan ID: '3a9d8460-fba7-438d-a013-f5ede4f627e9'
New stream: 'primary'
+-----------+------------+------------+------------+------------+
| seq_num | time | motor1 | motor2 | det4 |
+-----------+------------+------------+------------+------------+
| 1 | 13:54:19.1 | -1.500 | -0.100 | 0.323 |
| 2 | 13:54:19.2 | -1.200 | -0.080 | 0.485 |
| 3 | 13:54:19.2 | -0.900 | -0.060 | 0.666 |
| 4 | 13:54:19.3 | -0.600 | -0.040 | 0.835 |
| 5 | 13:54:19.4 | -0.300 | -0.020 | 0.956 |
| 6 | 13:54:19.4 | 0.000 | 0.000 | 1.000 |
| 7 | 13:54:19.5 | 0.300 | 0.020 | 0.956 |
| 8 | 13:54:19.5 | 0.600 | 0.040 | 0.835 |
| 9 | 13:54:19.6 | 0.900 | 0.060 | 0.666 |
| 10 | 13:54:19.6 | 1.200 | 0.080 | 0.485 |
| 11 | 13:54:19.7 | 1.500 | 0.100 | 0.323 |
+-----------+------------+------------+------------+------------+
generator scan ['3a9d8460'] (scan num: 4)
Out[6]: ('3a9d8460-fba7-438d-a013-f5ede4f627e9',)
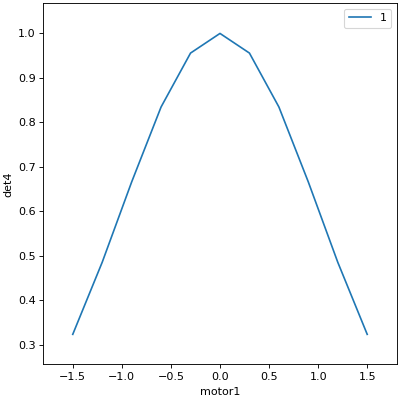
This works for any number of motors, not just two. Try importing motor3
from ophyd.sim and running a 3-motor scan.
To move motors along arbitrary trajectories instead of equally-spaced points,
use list_scan() and rel_list_scan().
from bluesky.plans import list_scan
# Scan motor1 and motor2 jointly through a 5-point trajectory.
RE(list_scan(dets, motor1, [1, 1, 3, 5, 8], motor2, [25, 16, 9, 4, 1]))
Demo:
In [7]: RE(list_scan(dets,
...: motor1, [1, 1, 3, 5, 8],
...: motor2, [25, 16, 9, 4, 1]))
...:
Transient Scan ID: 5 Time: 2026-07-13 13:54:21
Persistent Unique Scan ID: '246943ad-76a2-4147-b08d-166f74403106'
New stream: 'primary'
+-----------+------------+------------+------------+------------+
| seq_num | time | motor1 | motor2 | det4 |
+-----------+------------+------------+------------+------------+
| 1 | 13:54:21.3 | 1.000 | 25.000 | 0.000 |
| 2 | 13:54:21.3 | 1.000 | 16.000 | 0.000 |
| 3 | 13:54:21.4 | 3.000 | 9.000 | 0.000 |
| 4 | 13:54:21.4 | 5.000 | 4.000 | 0.000 |
| 5 | 13:54:21.5 | 8.000 | 1.000 | 0.000 |
+-----------+------------+------------+------------+------------+
generator list_scan ['246943ad'] (scan num: 5)
Out[7]: ('246943ad-76a2-4147-b08d-166f74403106',)
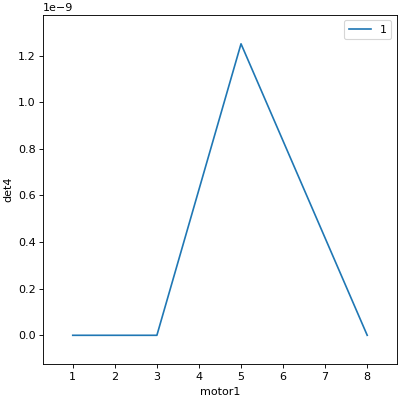
Scan Multiple Motors in a Grid#
In this case scan N motors through an N-dimensional rectangular grid. We’ll use the same simulated hardware as in the previous section:
from ophyd.sim import det4, motor1, motor2, motor3
dets = [det4] # just one in this case, but it could be more than one
We’ll use a new plan, named grid_scan().
from bluesky.plans import grid_scan
Let’s start with a 3x5x5 grid.
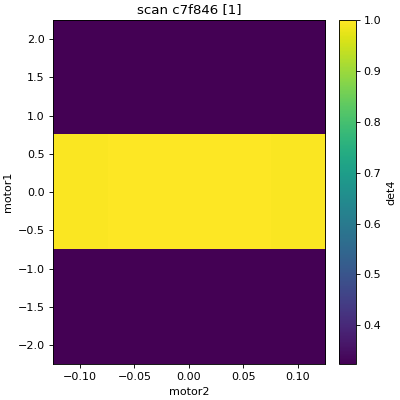
RE(grid_scan(dets,
motor1, -1.5, 1.5, 3, # scan motor1 from -1.5 to 1.5 in 3 steps
motor2, -0.1, 0.1, 5, # scan motor2 from -0.1 to 0.1 in 5 steps
motor3, 10, -10, 5)) # scan motor3 from 10 to -10 in 5 steps
Note that this will not plot an output as it is more axes than can currently be displayed.
The order of the motors controls how the grid is traversed. The “slowest” axis comes first. Numpy users will appreciate that this is consistent with numpy’s convention for indexing multidimensional arrays.
The optional parameter snake_axes can be used to control which motors’
trajectories “snake” back and forth. A snake-like path is usually more
efficient, but it is not suitable for certain hardware, so it is disabled by
default. To enable snaking for specific axes, give a list like
snake_axes=[motor2]. Since the first (slowest) axis is only traversed
once, it is not eligible to be included in snake_axes. As a convenience,
you may use snake_axes=True to enable snaking for all except that first
axis.
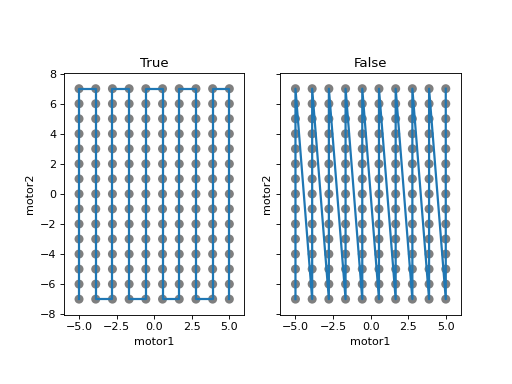
Demo:
In [8]: RE(grid_scan(dets,
...: motor1, -1.5, 1.5, 3, # scan motor1 from -1.5 to 1.5 in 3 steps
...: motor2, -0.1, 0.1, 5)) # scan motor2 from -0.1 to 0.1 in 5 steps
...:
Transient Scan ID: 6 Time: 2026-07-13 13:54:24
Persistent Unique Scan ID: 'adbd9dd9-7153-49df-b69b-6ae704f9ed4d'
New stream: 'primary'
+-----------+------------+------------+------------+------------+
| seq_num | time | motor1 | motor2 | det4 |
+-----------+------------+------------+------------+------------+
| 1 | 13:54:24.1 | -1.500 | -0.100 | 0.323 |
| 2 | 13:54:24.3 | -1.500 | -0.050 | 0.324 |
| 3 | 13:54:24.4 | -1.500 | 0.000 | 0.325 |
| 4 | 13:54:24.5 | -1.500 | 0.050 | 0.324 |
| 5 | 13:54:24.6 | -1.500 | 0.100 | 0.323 |
| 6 | 13:54:24.7 | 0.000 | -0.100 | 0.995 |
| 7 | 13:54:24.8 | 0.000 | -0.050 | 0.999 |
| 8 | 13:54:24.9 | 0.000 | 0.000 | 1.000 |
| 9 | 13:54:25.1 | 0.000 | 0.050 | 0.999 |
| 10 | 13:54:25.2 | 0.000 | 0.100 | 0.995 |
| 11 | 13:54:25.3 | 1.500 | -0.100 | 0.323 |
| 12 | 13:54:25.4 | 1.500 | -0.050 | 0.324 |
| 13 | 13:54:25.5 | 1.500 | 0.000 | 0.325 |
| 14 | 13:54:25.6 | 1.500 | 0.050 | 0.324 |
| 15 | 13:54:25.7 | 1.500 | 0.100 | 0.323 |
+-----------+------------+------------+------------+------------+
generator grid_scan ['adbd9dd9'] (scan num: 6)
Out[8]: ('adbd9dd9-7153-49df-b69b-6ae704f9ed4d',)
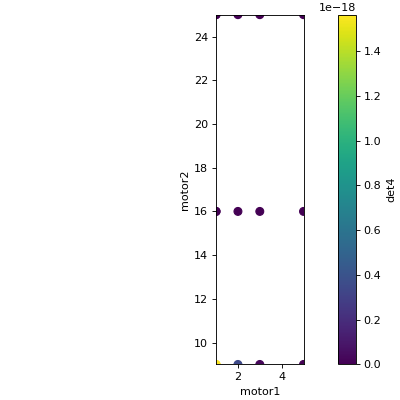
To move motors along arbitrary trajectories instead of equally-spaced points,
use list_grid_scan() and
rel_list_grid_scan().
from bluesky.plans import list_grid_scan
RE(list_grid_scan(dets,
motor1, [1, 1, 2, 3, 5],
motor2, [25, 16, 9]))
Demo:
In [9]: RE(list_grid_scan(dets,
...: motor1, [1, 1, 2, 3, 5],
...: motor2, [25, 16, 9]))
...:
Transient Scan ID: 7 Time: 2026-07-13 13:54:28
Persistent Unique Scan ID: 'bd3279e7-9cb0-4392-9ab9-1d53c52fa8fe'
New stream: 'primary'
+-----------+------------+------------+------------+------------+
| seq_num | time | motor1 | motor2 | det4 |
+-----------+------------+------------+------------+------------+
| 1 | 13:54:28.4 | 1.000 | 25.000 | 0.000 |
| 2 | 13:54:28.5 | 1.000 | 16.000 | 0.000 |
| 3 | 13:54:28.5 | 1.000 | 9.000 | 0.000 |
| 4 | 13:54:28.6 | 1.000 | 25.000 | 0.000 |
| 5 | 13:54:28.7 | 1.000 | 16.000 | 0.000 |
| 6 | 13:54:28.8 | 1.000 | 9.000 | 0.000 |
| 7 | 13:54:28.9 | 2.000 | 25.000 | 0.000 |
| 8 | 13:54:28.9 | 2.000 | 16.000 | 0.000 |
| 9 | 13:54:29.0 | 2.000 | 9.000 | 0.000 |
| 10 | 13:54:29.1 | 3.000 | 25.000 | 0.000 |
| 11 | 13:54:29.2 | 3.000 | 16.000 | 0.000 |
| 12 | 13:54:29.3 | 3.000 | 9.000 | 0.000 |
| 13 | 13:54:29.3 | 5.000 | 25.000 | 0.000 |
| 14 | 13:54:29.4 | 5.000 | 16.000 | 0.000 |
| 15 | 13:54:29.5 | 5.000 | 9.000 | 0.000 |
+-----------+------------+------------+------------+------------+
generator list_grid_scan ['bd3279e7'] (scan num: 7)
Out[9]: ('bd3279e7-9cb0-4392-9ab9-1d53c52fa8fe',)
See Multi-dimensional scans to handle more specialized cases, including
combinations of scan()-like and
grid_scan()-like movement.
More generally, the Plans documentation includes more exotic trajectories, such as spirals, and plans with adaptive logic, such as efficient peak-finders.
Aside: Access Saved Data#
At this point it is natural to wonder, “How do I access my saved data?” From the point of view of bluesky, that’s really not bluesky’s concern, but it’s a reasonable question, so we’ll address a typical scenario.
Note
This section presumes that you are using Tiled. (We configured a local server and client in an earlier section of this tutorial.) You don’t have to use Tiled to use bluesky; it’s just one convenient way to capture the metadata and data generated by the RunEngine.
Very briefly, you can access saved data by referring to a dataset (a “run”) by its unique ID, which is returned by the RunEngine at collection time.
In [10]: from bluesky.plans import count
In [11]: from ophyd.sim import det
In [12]: uid, = RE(count([det], num=3))
Transient Scan ID: 8 Time: 2026-07-13 13:54:31
Persistent Unique Scan ID: '108e2e1b-57ed-413f-a78c-fa6e27c2332a'
New stream: 'primary'
+-----------+------------+------------+
| seq_num | time | det |
+-----------+------------+------------+
| 1 | 13:54:31.6 | 0.607 |
| 2 | 13:54:31.7 | 0.607 |
| 3 | 13:54:31.7 | 0.607 |
+-----------+------------+------------+
generator count ['108e2e1b'] (scan num: 8)
In [13]: run = db[uid]
Alternatively, perhaps more conveniently, you can access it by recency:
In [14]: run = db.values()[-1] # meaning '1 run ago', i.e. the most recent run
Note
We assumed above that the plan generated one “run” (dataset), which is
typical for simple plans like count(). In the
general case, a plan can generate multiple runs, returning multiple uids,
which in turn lets you look up multiple runs.
uids = RE(some_plan(...))
runs = [db[uid] for uid in uids]
Most of the useful metadata is in this dictionary:
In [15]: run.start
Out[15]:
{'uid': '108e2e1b-57ed-413f-a78c-fa6e27c2332a',
'time': 1783950871.566271,
'versions': {'ophyd': '1.11.2',
'bluesky': '1.15.2.dev56+gf29386297',
'event_model': '1.24.0'},
'scan_id': 8,
'plan_type': 'generator',
'plan_name': 'count',
'detectors': ['det'],
'num_points': 3,
'num_intervals': 2,
'plan_args': {'detectors': ["SynGauss(prefix='', name='det', read_attrs=['val'], configuration_attrs=['Imax', 'center', 'sigma', 'noise', 'noise_multiplier'])"],
'num': 3,
'delay': 0.0},
'hints': {'dimensions': [[['time'], 'primary']]}}
And the (“primary”) stream of data is accessible like so:
In [16]: run["primary"].read()
Out[16]:
<xarray.Dataset> Size: 48B
Dimensions: (dim0: 3)
Dimensions without coordinates: dim0
Data variables:
time (dim0) float64 24B 1.784e+09 1.784e+09 1.784e+09
det (dim0) float64 24B 0.6065 0.6065 0.6065
From here we refer to the Tiled documentation.
Simple Customization#
Save Some Typing with ‘Partial’#
Suppose we nearly always use the same detector(s) and we tire of typing out
count([det]). We can write a custom variant of count()
using a built-in function provided by Python itself, functools.partial().
from functools import partial
from bluesky.plans import count
from ophyd.sim import det
my_count = partial(count, [det])
RE(my_count()) # equivalent to RE(count([det]))
# Additional arguments to my_count() are passed through to count().
RE(my_count(num=3, delay=1))
Plans in Series#
A custom plan can dispatch out to other plans using the Python syntax
yield from. (See appendix if you want to know
why.) Examples:
from bluesky.plans import scan
def coarse_and_fine(detectors, motor, start, stop):
"Scan from 'start' to 'stop' in 10 steps and then again in 100 steps."
yield from scan(detectors, motor, start, stop, 10)
yield from scan(detectors, motor, start, stop, 100)
RE(coarse_and_fine(dets, motor, -1, 1))
All of the plans introduced thus far, which we imported from
bluesky.plans, generate data sets (“runs”). Plans in the
bluesky.plan_stubs module do smaller operations. They can be used alone
or combined to build custom plans.
The mv() plan moves one or more devices and waits for
them all to arrive.
from bluesky.plan_stubs import mv
from ophyd.sim import motor1, motor2
# Move motor1 to 1 and motor2 to 10, simultaneously. Wait for both to arrive.
RE(mv(motor1, 1, motor2, 10))
We can combine mv() and count()
into one plan like so:
def move_then_count():
"Move motor1 and motor2 into position; then count det."
yield from mv(motor1, 1, motor2, 10)
yield from count(dets)
RE(move_then_count())
It’s very important to remember the yield from. The following plan does
nothing at all! (The plans inside it will be defined but never executed.)
# WRONG EXAMPLE!
def oops():
"Forgot 'yield from'!"
mv(motor1, 1, motor2, 10)
count(dets)
Much richer customization is possible, but we’ll leave that for a a later section of this tutorial. See also the complete list of plan stubs.
Warning
Never put ``RE(…)`` inside a loop or a function. You should always call it directly — typed by the user at the terminal — and only once.
You might be tempted to write a script like this:
from bluesky.plans import scan
from ophyd.sim import motor, det
# Don't do this!
for j in [1, 2, 3]:
print(j, 'steps')
RE(scan([det], motor, 5, 10, j)))
Or a function like this:
# Don't do this!
def bad_function():
for j in [1, 2, 3]:
print(j, 'steps')
RE(scan([det], motor, 5, 10, j)))
But, instead, you should do this:
from bluesky.plans import scan
from ophyd.sim import motor, det
def good_plan():
for j in [1, 2, 3]:
print(j, 'steps')
yield from scan([det], motor, 5, 10, j)
RE(my_plan())
If you try to hide RE inside a function, someone later might
use that function inside another function, and now we’re entering and
exiting the RunEngine multiple times from a single prompt. This can lead
to unexpected behavior, especially around handling interruptions and
errors.
To indulge a musical metaphor, the plan is the sheet music, the hardware is the orchestra, and the RunEngine is the conductor. There should be only one conductor and she needs to run whole show, start to finish.
“Baseline” Readings (and other Supplemental Data)#
In addition to the detector(s) and motor(s) of primary interest during an experiment, it is commonly useful to take a snapshot (“baseline reading”) of other hardware. This information is typically used to check consistency over time. (“Is the temperature of the sample mount roughly the same as it was last week?”) Ideally, we’d like to automatically capture readings from these devices during all future experiments without any extra thought or typing per experiment. Bluesky provides a specific solution for this.
Configure#
Note
If you are visiting user at a facility that runs bluesky, you may not need to do this configuration, and you can skip the next subsection just below — Choose “Baseline” Devices.
You can type sd to check. If you get something like:
In [17]: sd
Out[17]: SupplementalData(baseline=[], monitors=[], flyers=[])
you should skip this configuration.
Before we begin, we have to do a little more RunEngine configuration, like what
we did in the The RunEngine section with RE.subscribe.
from bluesky.preprocessors import SupplementalData
sd = SupplementalData()
RE.preprocessors.append(sd)
Choose “Baseline” Devices#
We’ll choose the detectors/motors that we want to be read automatically at the
beginning and end of each dataset (“run”). If you are using a shared
configuration, this also might already have been done, so you should check the
content of sd.baseline before altering it.
In [18]: sd.baseline # currently empty
Out[18]: []
Suppose that we want to take baseline readings from three detectors and two
motors. We’ll import a handful of simulated devices for this purpose, put them
into a list, and assign sd.baseline.
In [19]: from ophyd.sim import det1, det2, det3, motor1, motor2
In [20]: sd.baseline = [det1, det2, det3, motor1, motor2]
Notice that we can put a mixture of detectors and motors in this list. It doesn’t matter to bluesky that some are movable and some are not because it’s just going to be reading them, and both detectors and motors can be read.
Use#
Now we can just do a scan with the detector and motor of primary interest. The RunEngine will automatically take baseline readings before and after each run. Demo:
In [21]: from ophyd.sim import det, motor
In [22]: from bluesky.plans import scan
In [23]: RE(scan([det], motor, -1, 1, 5))
Transient Scan ID: 9 Time: 2026-07-13 13:54:32
Persistent Unique Scan ID: '3e329ea1-e6c4-4df8-abf8-547df3772ab6'
New stream: 'baseline'
Start-of-run baseline readings:
+--------------------------------+--------------------------------+
| det1 | 9.643749239819588e-22 |
| det2 | 0.0006709252558050237 |
| det3 | 1.2130613194252668 |
| motor1 | 5.0 |
| motor2 | 9.0 |
+--------------------------------+--------------------------------+
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | motor | det |
+-----------+------------+------------+------------+
| 1 | 13:54:32.4 | -1.000 | 0.607 |
| 2 | 13:54:32.5 | -0.500 | 0.882 |
| 3 | 13:54:32.5 | 0.000 | 1.000 |
| 4 | 13:54:32.6 | 0.500 | 0.882 |
| 5 | 13:54:32.6 | 1.000 | 0.607 |
+-----------+------------+------------+------------+
generator scan ['3e329ea1'] (scan num: 9)
End-of-run baseline readings:
+--------------------------------+--------------------------------+
| det1 | 9.643749239819588e-22 |
| det2 | 0.0006709252558050237 |
| det3 | 1.2130613194252668 |
| motor1 | 5.0 |
| motor2 | 9.0 |
+--------------------------------+--------------------------------+
Out[23]: ('3e329ea1-e6c4-4df8-abf8-547df3772ab6',)
We can clear or update the list of baseline detectors at any time.
In [24]: sd.baseline = []
As an aside, this is one place where the design of bluesky really pays off. By separating the executor (the RunEngine) from the instruction sets (the plans) it’s easy to apply global configuration without updating every plan individually.
Access Baseline Data#
If you access the data from our baseline scan, you might think that the baseline data is missing!
In [25]: run = db.values()[-1]
In [26]: run["primary"].read()
Out[26]:
<xarray.Dataset> Size: 160B
Dimensions: (dim0: 5)
Dimensions without coordinates: dim0
Data variables:
time (dim0) float64 40B 1.784e+09 1.784e+09 ... 1.784e+09
motor_setpoint (dim0) float64 40B -1.0 -0.5 0.0 0.5 1.0
det (dim0) float64 40B 0.6065 0.8825 1.0 0.8825 0.6065
motor (dim0) float64 40B -1.0 -0.5 0.0 0.5 1.0
Looking again at the output when we executed this scan, notice these lines:
New stream: 'baseline'
...
New stream: 'primary'
The “primary” stream contains the event data from the main body of the scan:
In [27]: run["primary"].read()
Out[27]:
<xarray.Dataset> Size: 160B
Dimensions: (dim0: 5)
Dimensions without coordinates: dim0
Data variables:
time (dim0) float64 40B 1.784e+09 1.784e+09 ... 1.784e+09
motor_setpoint (dim0) float64 40B -1.0 -0.5 0.0 0.5 1.0
det (dim0) float64 40B 0.6065 0.8825 1.0 0.8825 0.6065
motor (dim0) float64 40B -1.0 -0.5 0.0 0.5 1.0
We can access other streams by name.
In [28]: run["baseline"].read()
Out[28]:
<xarray.Dataset> Size: 128B
Dimensions: (dim0: 2)
Dimensions without coordinates: dim0
Data variables:
det3 (dim0) float64 16B 1.213 1.213
motor1 (dim0) float64 16B 5.0 5.0
motor2_setpoint (dim0) int64 16B 9 9
motor2 (dim0) float64 16B 9.0 9.0
time (dim0) float64 16B 1.784e+09 1.784e+09
det2 (dim0) float64 16B 0.0006709 0.0006709
det1 (dim0) float64 16B 9.644e-22 9.644e-22
motor1_setpoint (dim0) int64 16B 5 5
A list of the stream names in a given run is available as
list(run). From here we refer to the
Tiled documentation.
Other Supplemental Data#
Above, we used sd.baseline. There is also sd.monitors for signals to
monitor asynchronously during a run and sd.flyers for devices to “fly-scan”
during a run. See Supplemental Data for details.
Pause, Resume, Suspend#
Interactive Pause & Resume#
Sometimes it is convenient to pause data collection, check on some things, and then either resume from where you left off or quit. The RunEngine makes it possible to do this cleanly and safely on any plan, including user-defined plans, with minimal effort by the user. Of course, experiments on systems that evolve with time can’t be arbitrarily paused and resumed. It’s up to the user to know that and use this feature only when applicable.
Take this example, a step scan over ten points.
from ophyd.sim import det, motor
from bluesky.plans import scan
motor.delay = 1 # simulate slow motor movement
RE(scan([det], motor, 1, 10, 10))
Demo:
In [29]: RE(scan([det], motor, 1, 10, 10))
Transient Scan ID: 1 Time: 2018/02/12 12:40:36
Persistent Unique Scan ID: 'c5db9bb4-fb7f-49f4-948b-72fb716d1f67'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | motor | det |
+-----------+------------+------------+------------+
| 1 | 12:40:37.6 | 1.000 | 0.607 |
| 2 | 12:40:38.7 | 2.000 | 0.135 |
| 3 | 12:40:39.7 | 3.000 | 0.011 |
At this point we decide to hit Ctrl+C (SIGINT). The RunEngine will catch this signal and react like so. We will examine this output piece by piece.
^C
A 'deferred pause' has been requested.The RunEngine will pause at the next
checkpoint. To pause immediately, hit Ctrl+C again in the next 10 seconds.
Deferred pause acknowledged. Continuing to checkpoint.
<...a few seconds later...>
| 4 | 12:40:40.7 | 4.000 | 0.000 |
Pausing...
---------------------------------------------------------------------------
RunEngineInterrupted Traceback (most recent call last)
<ipython-input-14-826ee9dfb918> in <module>()
----> 1 RE(scan([det], motor, 1, 10, 10))
<...snipped details...>
RunEngineInterrupted:
Your RunEngine is entering a paused state. These are your options for changing
the state of the RunEngine:
RE.resume() Resume the plan.
RE.abort() Perform cleanup, then kill plan. Mark exit_status='abort'.
RE.stop() Perform cleanup, then kill plan. Mark exit_status='success'.
RE.halt() Emergency Stop: Do not perform cleanup --- just stop.
When it pauses, the RunEngine immediately tells all Devices that it has touched
so far to “stop”. (Devices define what that means to them in their stop()
method.) This is not a replacement for proper equipment protection; it is just
a convenience.
Now, at our leisure, we may:
pause to think
investigate the state of our hardware, such as the detector’s exposure time
turn on more verbose logging (see Debugging and Logging)
decide whether to stop here or resume
Suppose we decide to resume. The RunEngine will pick up from the last “checkpoint”. Typically, this means beginning of each step in a scan, but plans may specify checkpoints anywhere they like.
In [30]: RE.resume()
| 5 | 12:40:50.1 | 5.000 | 0.000 |
| 6 | 12:40:51.1 | 6.000 | 0.000 |
| 7 | 12:40:52.1 | 7.000 | 0.000 |
| 8 | 12:40:53.1 | 8.000 | 0.000 |
| 9 | 12:40:54.1 | 9.000 | 0.000 |
| 10 | 12:40:55.1 | 10.000 | 0.000 |
+-----------+------------+------------+------------+
generator scan ['c5db9bb4'] (scan num: 1)
The scan has completed successfully.
If you go back and read the output from when we hit Ctrl+C, you will notice that the RunEngine didn’t pause immediately: it finished the current step of the scan first. Quoting an excerpt from the demo above:
^C
A 'deferred pause' has been requested.The RunEngine will pause at the next
checkpoint. To pause immediately, hit Ctrl+C again in the next 10 seconds.
Deferred pause acknowledged. Continuing to checkpoint.
<...a few seconds later...>
| 4 | 12:40:40.7 | 4.000 | 0.000 |
Pausing...
Observe that hitting Ctrl+C twice pauses immediately, without waiting to finish the current step.
In [2]: RE(scan([det], motor, 1, 10, 10))
Transient Scan ID: 2 Time: 2018/02/15 12:31:14
Persistent Unique Scan ID: 'b342448f-6a64-4f26-91a6-37f559cb5537'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | motor | det |
+-----------+------------+------------+------------+
| 1 | 12:31:15.8 | 1.000 | 0.607 |
| 2 | 12:31:16.8 | 2.000 | 0.135 |
| 3 | 12:31:17.8 | 3.000 | 0.011 |
^C^C
Pausing...
When resumed, the RunEngine will rewind to the last checkpoint (the beginning of the fourth step in the scan) and repeat instructions as needed.
Quoting again from the demo, notice that RE.resume() was only one of our
options. If we decide not to continue we can quit in three different ways:
Your RunEngine is entering a paused state. These are your options for changing
the state of the RunEngine:
RE.resume() Resume the plan.
RE.abort() Perform cleanup, then kill plan. Mark exit_status='abort'.
RE.stop() Perform cleanup, then kill plan. Mark exit_status='success'.
RE.halt() Emergency Stop: Do not perform cleanup --- just stop.
“Aborting” and “stopping” are almost the same thing: they just record different
metadata about why the experiment was ended. Both signal to the plan that it
should end early, but they still let it specify more instructions so that it
can “clean up.” For example, a rel_scan() moves the motor
back to its starting position before quitting.
In rare cases, if we are worried that the plan’s cleanup procedure might be dangerous, we can “halt”. Halting circumvents the cleanup instructions.
Try executing RE(scan([det], motor, 1, 10, 10)), pausing, and exiting in
these various ways. Observe that the RunEngine won’t let you run a new plan
until you have resolved the paused plan using one of these methods.
Automated Suspend & Resume#
The RunEngine can be configured in advance to automatically pause and resume in response to external signals. To distinguish automatic pause/resume from interactive, user-initiated pause and resume, we call this behavior “suspending.”
For details, see Automated Suspension.
Metadata#
If users pass extra keyword arguments to RE, they are interpreted as
metadata
RE(count([det]), user='Dan', mood='skeptical')
RE(count([det]), user='Dan', mood='optimistic')
and they can be used for searching later:
headers = db(user='Dan')
headers = db(mood='skeptical')
Metadata can also be added persistently (i.e. applied to all future runs
until removed) by editing the dictionary RE.md.
RE.md
RE.md['user'] = 'Dan'
No need to specify user every time now….
RE(count([det])) # automatically includes user='Dan'
The key can be temporarily overridden:
RE(count([det]), user='Tom') # overrides the setting in RE.md, just once
or deleted:
del RE.md['user']
In addition to any user-provided metadata, the RunEngine, the devices, and the plan capture some metadata automatically. For more see, Recording Metadata.
Simulate and Introspect Plans#
We have referred to a plan as a “sequence of instructions encoding an experimental procedure.” But what’s inside a plan really? Bluesky calls each atomic instruction inside a plan a message. Handling the messages directly is only necessary when debugging or doing unusually deep customization, but it’s helpful to see them at least once before moving on to more practical tools.
Try printing out every message in a couple simple plans:
from bluesky.plans import count
from ophyd.sim import det
for msg in count([]):
print(msg)
for msg in count([det]):
print(msg)
See the Message Protocol section for more.
Bluesky includes some tools for producing more useful, human-readable summaries to answer the question, “What will this plan do?”
In [31]: from bluesky.simulators import summarize_plan
In [32]: from bluesky.plans import count, rel_scan
In [33]: from ophyd.sim import det, motor
# Count a detector 3 times.
In [34]: summarize_plan(count([det], 3))
=================================== Open Run ===================================
Read ['det']
Read ['det']
Read ['det']
================================== Close Run ===================================
# A 3-step scan.
In [35]: summarize_plan(rel_scan([det], motor, -1, 1, 3))
=================================== Open Run ===================================
motor -> 0.0
Read ['det', 'motor']
motor -> 1.0
Read ['det', 'motor']
motor -> 2.0
Read ['det', 'motor']
================================== Close Run ===================================
motor -> 1.0
For more possibilities, see Simulation and Error Checking.
Devices#
Theory#
The notion of a “Device” serves two goals:
Provide a standard interface to all hardware for the sake of generality and code reuse.
Logically group individual signals into composite “Devices” that can be read together, as a unit, and configured in a coordinated way. Provide a human-readable name to this group, with an eye toward later data analysis.
In bluesky’s view of the world, there are only three different kinds of devices used in data acquisition.
Some devices can be read. This includes simple points detectors that produce a single number and large CCD detectors that produce big arrays.
Some devices can be both read and set. Setting a motor physically moves it to a new position. Setting a temperature controller impels it to gradually change its temperature. Setting the exposure time on some detector promptly updates its configuration.
Some devices produce data at a rate too high to be read out in real time, and instead buffer their data externally in separate hardware or software until it can be read out.
Bluesky interacts with all devices via a specified interface.
Each device is represented by a Python object with certain methods and
attributes (with names like read and set). Some of these methods are
asynchronous, such as set, which allows for the concurrent movement of
multiple devices.
Implementation#
Ophyd, a Python library that was developed in tandem with bluesky, implements this interface for devices that speak EPICS. But bluesky is not tied to ophyd or EPICS specifically: any Python object may be used, so long as it provides the specified methods and attributes that bluesky expects. For example, an experimental implementation of the bluesky interface for LabView has been written. See Hardware Interface Packages for more examples. And the simulated hardware that we have been using in this tutorial is all based on pure-Python constructs unconnected from hardware or any specific hardware control protocol.
To get a flavor for what it looks like to configure hardware in ophyd, connecting to an EPICS motor looks like this:
from ophyd import EpicsMotor
nano_top_x = EpicsMotor('XF:31ID-ES{Dif:Nano-Ax:TopX}Mtr', name='nano_top_x')
We have provided both the machine-readable address of the motor on the network,
'XF:31ID-ES{Dif:Nano-Ax:TopX}Mtr' (in EPICS jargon, the “PV” for
“Process Variable”), and a human-readable name, 'nano_top_x', which will be
used to label the data generated by this motor. When it comes time to analyze
the data, we will be grateful to be dealing with the human-readable label.
The EpicsMotor device is a logical grouping of many signals. The most
important are the readback (actual position) and setpoint (target position).
All of the signals are summarized thus. The details here aren’t important at
this stage: the take-away message is, “There is a lot of stuff to keep track of
about a motor, and a Device helpfully groups that stuff for us.”
In [3]: nano_top_x.summary()
data keys (* hints)
-------------------
*nano_top_x
nano_top_x_user_setpoint
read attrs
----------
user_readback EpicsSignalRO ('nano_top_x')
user_setpoint EpicsSignal ('nano_top_x_user_setpoint')
config keys
-----------
nano_top_x_acceleration
nano_top_x_motor_egu
nano_top_x_user_offset
nano_top_x_user_offset_dir
nano_top_x_velocity
configuration attrs
----------
motor_egu EpicsSignal ('nano_top_x_motor_egu')
velocity EpicsSignal ('nano_top_x_velocity')
acceleration EpicsSignal ('nano_top_x_acceleration')
user_offset EpicsSignal ('nano_top_x_user_offset')
user_offset_dir EpicsSignal ('nano_top_x_user_offset_dir')
Unused attrs
------------
offset_freeze_switch EpicsSignal ('nano_top_x_offset_freeze_switch')
set_use_switch EpicsSignal ('nano_top_x_set_use_switch')
motor_is_moving EpicsSignalRO ('nano_top_x_motor_is_moving')
motor_done_move EpicsSignalRO ('nano_top_x_motor_done_move')
high_limit_switch EpicsSignal ('nano_top_x_high_limit_switch')
low_limit_switch EpicsSignal ('nano_top_x_low_limit_switch')
direction_of_travel EpicsSignal ('nano_top_x_direction_of_travel')
motor_stop EpicsSignal ('nano_top_x_motor_stop')
home_forward EpicsSignal ('nano_top_x_home_forward')
home_reverse EpicsSignal ('nano_top_x_home_reverse')
Write Custom Plans#
As mentioned in the Simple Customization section above, the
“pre-assembled” plans with count() and
scan() are built from smaller “plan stubs”. We can
mix and match the “stubs” and/or “pre-assembled” plans to build custom plans.
There are many of plan stubs, so it’s convenient to import the whole module and work with that.
import bluesky.plan_stubs as bps
Move in Parallel#
Before writing a custom plan to coordinate the motion of multiple devices, consider whether your use case could be addressed with one of the built-in Multi-dimensional scans.
We previously introduced the mv() plan that moves one
or more devices and waits for them all to arrive. There is also
mvr() for moving relative to the current position.
from ophyd.sim import motor1, motor2
# Move motor1 to 1 and motor2 10 units in the positive direction relative
# to their current positions. Wait for both to arrive.
RE(bps.mvr(motor1, 1, motor2, 10))
Some scenarios require more low-level control over when the waiting occurs.
For these, we employ wait() and
abs_set() (“absolute set”) or
rel_set() (“relative set”).
Here is a scenario that does require a custom solution: we want to set several motors in motion at once, including multiple fast motors and one slow motor. We want to wait for the fast motors to arrive, print a message, then wait for the slow motor to arrive, and print a second message.
def staggered_wait(fast_motors, slow_motor):
# Start all the motors, fast and slow, moving at once.
# Put all the fast_motors in one group...
for motor in fast_motors:
yield from bps.abs_set(motor, 5, group='A')
# ...but put the slow motor is separate group.
yield from bps.abs_set(slow_motor, 5, group='B')
# Wait for all the fast motors.
print('Waiting on the fast motors.')
yield from bps.wait('A')
print('Fast motors are in place. Just waiting on the slow one now.')
# Then wait for the slow motor.
yield from bps.wait('B')
print('Slow motor is in place.')
Sleeping (Timed Delays)#
Note
If you need to wait for your motor to finish moving, temperature to finish
equilibrating, or shutter to finish opening, inserting delays into plans
isn’t the best way to do that. It should be the Device’s business to
report accurately when it is done, including any extra padding for settling
or equilibration. On some devices, such as EpicsMotor, this can be
configured like motor.settle_time = 3.
For timed delays, bluesky has a special plan, which allows the RunEngine to continue its business during the sleep.
def sleepy_plan(motor, positions):
"Step a motor through a list of positions with 1-second delays between steps.")
for position in positions:
yield from bps.mv(motor, position)
yield from bps.sleep(1)
You should always use this plan, *never* Python’s built-in function
:func:`time.sleep`. Why?
The RunEngine uses an event loop to concurrently manage many tasks. It assumes
that none of those tasks blocks for very long. (A good figure for “very long”
is 0.2 seconds.) Therefore, you should never incorporate long blocking function
calls in your plan, such as time.sleep(1).
Capture Data#
Any plan that generates data must include instructions for grouping readings into Events (i.e. rows in a table) and grouping those Events into Runs (datasets that are given a “scan ID”). This is best explained by example.
import bluesky.plan_stubs as bps
def one_run_one_event(detectors):
# Declare the beginning of a new run.
yield from bps.open_run()
yield from bps.declare_stream(*detectors, name='primary')
# Trigger each detector and wait for triggering to complete.
# Then read the detectors and bundle these readings into an Event
# (i.e. one row in a table.)
yield from bps.trigger_and_read(detectors)
# Declare the end of the run.
yield from bps.close_run()
Execute the plan like so:
In [36]: RE(one_run_one_event([det1, det2]))
Transient Scan ID: 10 Time: 2026-07-13 13:54:33
Persistent Unique Scan ID: '2bc4e0e2-b98b-4897-97c4-b55ca77ac6df'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | det2 | det1 |
+-----------+------------+------------+------------+
| 1 | 13:54:33.7 | 0.001 | 0.000 |
+-----------+------------+------------+------------+
generator one_run_one_event ['2bc4e0e2'] (scan num: 10)
Out[36]: ('2bc4e0e2-b98b-4897-97c4-b55ca77ac6df',)
We observe:
one table (one Run)
one row (one Event)
two columns (a column for each detector)
Here’s the same plan again, with trigger_and_read()
moved inside a for loop.
def one_run_multi_events(detectors, num):
yield from bps.open_run()
yield from bps.declare_stream(*detectors, name='primary')
for i in range(num):
yield from bps.trigger_and_read(detectors)
yield from bps.close_run()
Execute the plan like so:
In [37]: RE(one_run_multi_events([det1, det2], 3))
Transient Scan ID: 11 Time: 2026-07-13 13:54:34
Persistent Unique Scan ID: '7ce955e6-c712-4b19-97f4-bf191788c865'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | det2 | det1 |
+-----------+------------+------------+------------+
| 1 | 13:54:34.4 | 0.001 | 0.000 |
| 2 | 13:54:34.6 | 0.001 | 0.000 |
| 3 | 13:54:34.8 | 0.001 | 0.000 |
+-----------+------------+------------+------------+
generator one_run_multi_events ['7ce955e6'] (scan num: 11)
Out[37]: ('7ce955e6-c712-4b19-97f4-bf191788c865',)
We observe:
one table (one Run)
three rows (three Events)
two columns (a column for each detector)
Finally, add another loop re-using one_run_multi_events inside that loop.
def multi_runs_multi_events(detectors, num, num_runs):
yield from bps.declare_stream(*detectors, name='primary')
for i in range(num_runs):
yield from one_run_multi_events(detectors, num)
In [38]: RE(multi_runs_multi_events([det1, det2], num=3, num_runs=2))
Transient Scan ID: 12 Time: 2026-07-13 13:54:35
Persistent Unique Scan ID: '5ba5f2b1-22b4-4da0-9636-1448afe6d465'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | det2 | det1 |
+-----------+------------+------------+------------+
| 1 | 13:54:35.4 | 0.001 | 0.000 |
| 2 | 13:54:35.7 | 0.001 | 0.000 |
| 3 | 13:54:35.9 | 0.001 | 0.000 |
+-----------+------------+------------+------------+
generator multi_runs_multi_events ['5ba5f2b1'] (scan num: 12)
Transient Scan ID: 13 Time: 2026-07-13 13:54:36
Persistent Unique Scan ID: '48c56a84-e286-4466-af00-1a5c62a1f0a0'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | det2 | det1 |
+-----------+------------+------------+------------+
| 1 | 13:54:36.5 | 0.001 | 0.000 |
| 2 | 13:54:36.7 | 0.001 | 0.000 |
| 3 | 13:54:36.9 | 0.001 | 0.000 |
+-----------+------------+------------+------------+
generator multi_runs_multi_events ['48c56a84'] (scan num: 13)
Out[38]:
('5ba5f2b1-22b4-4da0-9636-1448afe6d465',
'48c56a84-e286-4466-af00-1a5c62a1f0a0')
We observe:
two tables (two Runs)
three rows (three Events)
two columns (a column for each detector)
We also notice that the return value output from the RunEngine is a tuple with two unique IDs, one per Run generated by this plan.
In order to focus on the scope of an Event and a Run, we have left out an important detail, addressed in the next section, which may be necessary to incorporate before trying these plans on real devices.
Stage and Unstage#
Complex devices often require some preliminary setup before they can be used
for data collection, moving them from a resting state into a state where they
are ready to acquire data. Bluesky accommodates this in a general way by
allowing every Device to implement an optional stage() method, with a
corresponding unstage() method. Plans should stage every device that they
touch exactly once and unstage every device at the end. If a Device does not
have a stage() method the RunEngine will just skip over it.
Revising our simplest example above, one_run_one_event,
import bluesky.plan_stubs as bps
def one_run_one_event(detectors):
yield from bps.open_run()
yield from bps.declare_stream(*detectors, name='primary')
yield from bps.trigger_and_read(detectors)
yield from bps.close_run()
we incorporate staging like so:
def one_run_one_event(detectors):
# 'Stage' every device.
for det in detectors:
yield from bps.stage(det)
yield from bps.open_run()
yield from bps.declare_stream(*detectors, name='primary')
yield from bps.trigger_and_read(detectors)
yield from bps.close_run()
# 'Unstage' every device.
for det in detectors:
yield from bps.unstage(det)
This is starting to get verbose. At this point, we might want to accept some additional complexity in exchange for brevity — and some assurance that we don’t forget to use these plans in matching pairs. To that end, this plan is equivalent:
import bluesky.preprocessors as bpp
def one_run_one_event(detectors):
@bpp.stage_decorator(detectors)
def inner():
yield from bps.open_run()
yield from bps.declare_stream(*detectors, name='primary')
yield from bps.trigger_and_read(detectors)
yield from bps.close_run()
return (yield from inner())
The stage_decorator() is a plan preprocessor, a
plan which consumes another plan and modifies its instructions. In this case,
it adds inserts ‘stage’ and ‘unstage’ messages, supplanting
stage() and unstage(). We
can trim the verbosity down yet more by employing
run_decorator(), supplanting
open_run() and close_run().
The result:
import bluesky.preprocessors as bpp
def one_run_one_event(detectors):
@bpp.stage_decorator(detectors)
@bpp.run_decorator()
def inner():
yield from bps.declare_stream(*detectors, name='primary')
yield from bps.trigger_and_read(detectors)
return (yield from inner())
Incidentally, recall that we have already encountered a preprocessor in this
tutorial, in the section on baseline readings.
SupplementalData is a preprocessor.
Add Metadata#
To make it easier to search for data generated by the plan and to inspect what
was done afterward, we should include some metadata. We create a dictionary and
pass it to run_decorator() (or, in the more
verbose formulation, to open_run()). The RunEngine
will combine this metadata with any information provided by the user, as shown
in the the earlier section on metadata.
def one_run_one_event(detectors):
md = {
# Human-friendly names of detector Devices (useful for searching)
'detectors': [det.name for det in detectors],
# The Python 'repr's each argument to the plan
'plan_args': {'detectors': list(map(repr, detectors))},
# The name of this plan
'plan_name': 'one_run_one_event',
}
@bpp.stage_decorator(detectors)
@bpp.run_decorator(md)
def inner():
yield from bps.declare_stream(*detectors, name='primary')
yield from bps.trigger_and_read(detectors)
return (yield from inner())
Warning
The values in the metadata dictionary must be strings, numbers, lists/arrays, or dictionaries only. Metadata cannot contain arbitrary Python types because downstream consumers (like databases) do not know what to do with those and will error.
To be polite, we should allow the user to override this metadata. All of
bluesky’s “pre-assembled” plans (count(),
scan(), etc.) provide an optional md argument for this
purpose, implemented like so:
def one_run_one_event(detectors, md=None):
_md = {
'detectors': [det.name for det in detectors],
'plan_args': {'detectors': list(map(repr, detectors))},
'plan_name': 'one_run_one_event',
}
# If a key exists in md, it overwrites the default in _md.
_md.update(md or {})
@bpp.stage_decorator(detectors)
@bpp.run_decorator(_md)
def inner():
yield from bps.declare_stream(*detectors, name='primary')
yield from bps.trigger_and_read(detectors)
return (yield from inner())
Add “Hints” in Metadata#
The metadata dictionary may optionally include a key named 'hints'. This
key has special significance to the
BestEffortCallback and potentially
other downstream consumers, which use it to try to infer useful ways to
present the data. Currently, it solves two specific problems.
Narrow the potentially large set of readings to a manageable number of most important ones that fit into a table.
Identify the dimensionality of the data (1D scan? 2D grid? N-D grid?) and the dependent and independent parameters, for visualization and peak-fitting purposes.
It’s up to each device to address (1). The plan has no role in that.
Each device has an optional hints attribute with a value like
{'fields': [...]} to answer the question, “Of all the readings you
produce, what are the names of the most important ones?”
We need the plan to help us with (2). Only the plan can sort out which devices
are being employed as “independent” axes and which are being measured as
dependent variables. This isn’t clear just from looking at the Devices alone
because any given movable device can be used as an axis or as a “detector”
depending on the context — count([motor]) is a perfectly valid thing to
do!
The schema of the plan’s hint metadata is:
{'dimensions': [([<FIELD>, ...], <STREAM_NAME>),
([<FIELD>, ...], <STREAM_NAME>),
...
]}
Examples:
# a 1-D scan over x
{'dimensions': [(['x'], 'primary')]}
# a 2-D grid_scan over x and y
{'dimensions': [(['x'], 'primary'),
(['y'], 'primary')]}
# a scan moving x and y together along a diagonal
{'dimensions': [(['x', 'y'], 'primary')]}
# a 1-D scan over temperature, represented in C and K units
{'dimensions': [(['C', 'K'], 'primary')]}
# a 1-D scan over energy, as measured in energy and diffractometer position
{'dimensions': [(['E', 'dcm'], 'primary')]}
# special case: a sequence of readings where the independent axis is just time
{'dimensions': [(['time'], 'primary')]}
Each entry in the outer list represents one independent dimension. A dimension
might be represented by multiple fields, either from different devices moved in
a coordinated fashion by the plan (['x', 'y']), presented as fully redundant
information from one device (['C', 'K']), or coupled information from two
sub-devices (['E', 'dcm']).
The second element in each entry is the stream name: 'primary' in every
example above. This should correspond to the name passed into
trigger_and_read() or
create() inside the plan. The default name is
primary.
Putting it all together, the plan asks the device(s) being used as independent axes for their important field(s) and builds a list of dimensions like so:
dimensions = [(motor.hints['fields'], 'primary')]
We must account for the fact that hints is optional. A given Device
might not have a hints attribute at all and, even if it does, the
hints might not contain the 'fields' key that we are interested in. This
pattern silently omits the dimensions hint if the necessary information is not
provided by the Device:
def scan(..., md=None):
_md = {...}
_md.update(md or {})
try:
dimensions = [(motor.hints['fields'], 'primary')]
except (AttributeError, KeyError):
pass
else:
_md['hints'].setdefault('dimensions', dimensions)
...
Finally, by using setdefault, we have allowed user to override these hints
if they know better by passing in scan(..., md={'hints': ...}).
Adaptive Logic in a Plan#
Two-way communication is possible between the generator and the RunEngine.
For example, the trigger_and_read() plan responds with its readings. We
can use it to make an on-the-fly decision about whether to continue or stop.
import bluesky.preprocessors as bpp
import bluesky.plan_stubs as bps
from ophyd.sim import det, motor
def conditional_break(threshold):
"""Set, trigger, read until the detector reads intensity < threshold"""
@bpp.stage_decorator([det, motor])
@bpp.run_decorator()
def inner():
i = 0
yield from bps.declare_stream(det, name='primary')
while True:
yield from bps.mv(motor, i)
readings = yield from bps.trigger_and_read([det])
if readings['det']['value'] < threshold:
break
i += 1
return (yield from inner())
Demo:
In [39]: RE(conditional_break(0.2))
Transient Scan ID: 14 Time: 2026-07-13 13:54:37
Persistent Unique Scan ID: '1ee61236-1bbc-424f-8f58-fa14c6e03975'
New stream: 'primary'
+-----------+------------+------------+
| seq_num | time | det |
+-----------+------------+------------+
| 1 | 13:54:37.6 | 1.000 |
| 2 | 13:54:37.7 | 0.607 |
| 3 | 13:54:37.7 | 0.135 |
+-----------+------------+------------+
generator conditional_break ['1ee61236'] (scan num: 14)
Out[39]: ('1ee61236-1bbc-424f-8f58-fa14c6e03975',)
The important line in this example is
reading = yield from bps.trigger_and_read([det])
The action proceeds like this:
The plan yields a ‘read’ message to the RunEngine.
The RunEngine reads the detector.
The RunEngine sends that reading back to the plan, and that response is assigned to the variable
reading.
The response, reading, is formatted like:
{<name>: {'value': <value>, 'timestamp': <timestamp>}, ...}
For a detailed technical description of the messages and their responses, see Message Protocol.
Plan “Cleanup” (Exception Handling)#
If an exception is raised, the RunEngine gives the plan the opportunity to catch the exception and either handle it or merely yield some “clean up” messages before re-raising the exception and killing plan execution. (Recall this from Pause, Resume, Suspend above.)
This is the general idea:
# This example is illustrative, but it is not completely correct.
# Use `finalize_wrapper` instead (or read its source code).
def plan_with_cleanup():
def main_plan():
# do stuff...
def cleanup_plan():
# do other stuff...
try:
yield from main_plan()
finally:
# Do this even if an Exception is raised.
yield from cleanup_plan()
Note: The contingency_wrapper is superior to the finalize_wrapper as it accepts exceptions as arguments, allowing for targeted cleanup based on specific failure modes.
The exception in question may originate from the plan itself or from the RunEngine when it attempts to execute a given command.
The finalize_wrapper() preprocessor provides a
succinct and fully correct way of applying this general pattern.
import bluesky.preprocessors as bpp
def plan_with_cleanup():
yield from bpp.finalize_wrapper(main_plan(), cleanup_plan())
Further Reading#
Specifying checkpoints (TODO)
Monitoring (TODO)
Fly Scanning (TODO)
input_plan()(TODO)Going deeper than
trigger_and_read()(TODO)